每日經(jīng)濟(jì)新聞 2024-09-06 15:27:10
每經(jīng)記者|王嘉琦 每經(jīng)實習(xí)編輯|宋欣悅

在每日經(jīng)濟(jì)新聞于6月25日發(fā)布的《每日經(jīng)濟(jì)新聞大模型評測報告》第1期中,15款國內(nèi)外主流大模型在“財經(jīng)新聞標(biāo)題創(chuàng)作”“微博新聞寫作”“文章差錯校對”“財務(wù)數(shù)據(jù)計算與分析”四大實戰(zhàn)場景進(jìn)行了比拼。
隨著大模型的迭代更新和大模型新秀的涌現(xiàn),《每日經(jīng)濟(jì)新聞大模型評測報告》第2期如期而至。
第2期評測延續(xù)首期評測的宗旨,立足實戰(zhàn),力求為用戶展現(xiàn)大模型在具體工作場景中的真實表現(xiàn),為用戶在工作、學(xué)習(xí)和生活中選擇最佳大模型助手提供可靠參考。
本期評測設(shè)置了三個應(yīng)用場景:(1)金融數(shù)學(xué)計算;(2)商務(wù)文本翻譯;(3)財經(jīng)新聞閱讀。
每經(jīng)大模型評測小組為每個場景制定了相應(yīng)的評價維度和評分指標(biāo)。每日經(jīng)濟(jì)新聞10名資深記者、編輯根據(jù)評價維度和評分指標(biāo),對各款大模型在三大場景中的表現(xiàn)進(jìn)行評分,匯總各場景得分,最終得到參評大模型總分。
不同于首期,第2期評測中的任務(wù)以客觀題為主,絕大多數(shù)題目都有標(biāo)準(zhǔn)答案。同時,評價維度和評分標(biāo)準(zhǔn)也更加突出客觀性,盡量避免主觀性評價。
需要特別指出的是,本期評測是通過各款大模型的API端口,并在默認(rèn)溫度下完成。與公眾用戶使用的大模型C端對話工具存在差異。但評測結(jié)果對用戶在具體場景中選擇合適的大模型工具,依然具有重大參考價值。
本期評測在“雨燕智宣AI創(chuàng)作+”測試臺上進(jìn)行,參評模型包括GPT-4o、智譜GLM-4、百度文心ERNIE-4.0-Turbo等15款國內(nèi)外明星大模型。
本期評測時間為2024年8月12日,因此上述參評大模型中的所有國內(nèi)大模型均為截至8月12日的最新版本。

誰能在三大評測場景中脫穎而出?
經(jīng)過激烈角逐,評測結(jié)果新鮮出爐!
報告完整版以及測評題目,評分指標(biāo)細(xì)則及部分案例,可訪問:每日經(jīng)濟(jì)新聞大模型評測報告(第2期)。

評測結(jié)果顯示,“黑馬”幻方求索DeepSeek-V2以237.75的總分位居榜首,緊隨其后的是騰訊混元hunyuan-pro(237.08分)和Anthropic Claude 3.5 Sonnet(234.42分)。
在專項能力方面,各模型展現(xiàn)出了不同的優(yōu)勢。
金融數(shù)學(xué)計算方面,騰訊混元hunyuan-pro以78分的成績領(lǐng)先其他模型,排名第一,幻方求索DeepSeek-V2和商湯商量SenseChat V5.5緊隨其后。相比之下,零一萬物的Yi-Large、百度的文心ERNIE-4.0-Turbo以及昆侖天工的SkyChat-3.0則在金融數(shù)學(xué)計算方面表現(xiàn)稍顯遜色,分別位列倒數(shù)第三、倒數(shù)第二與倒數(shù)第一的位置。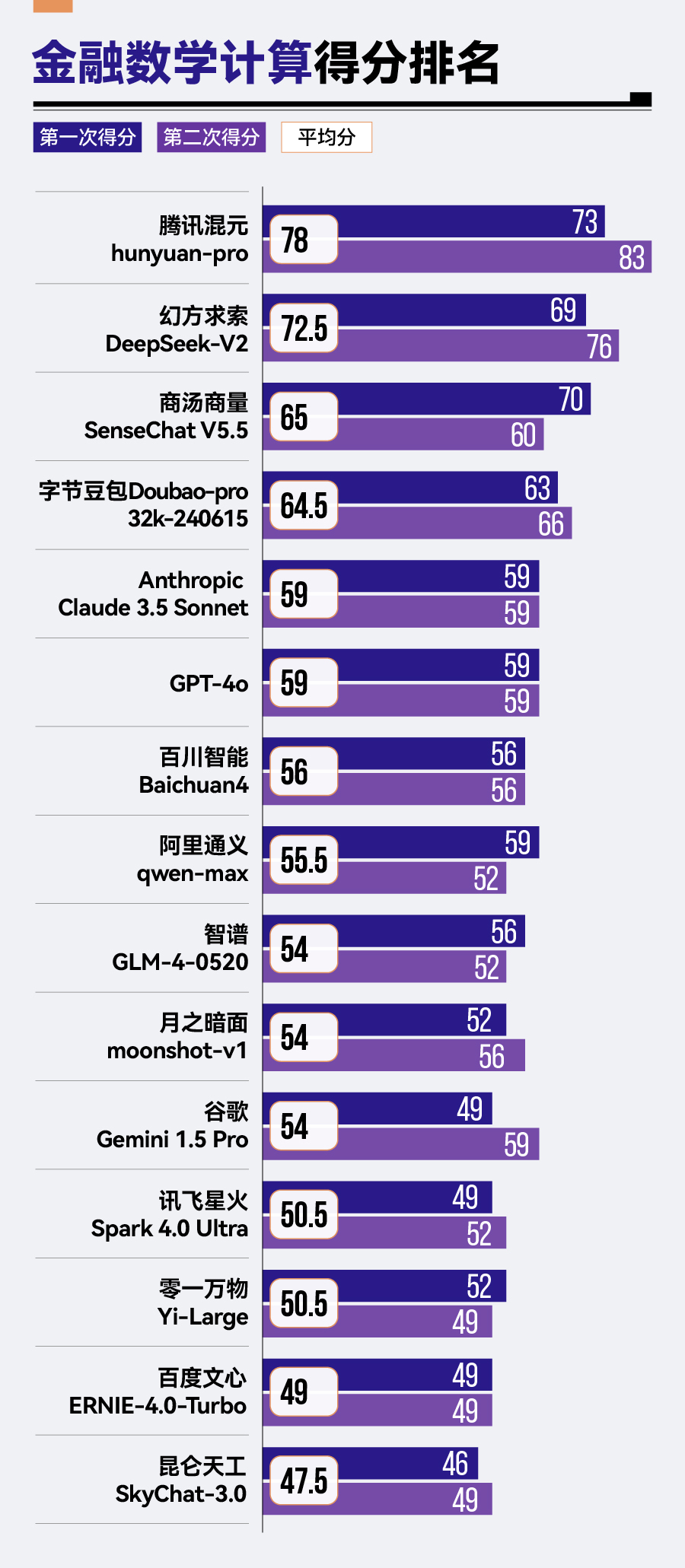
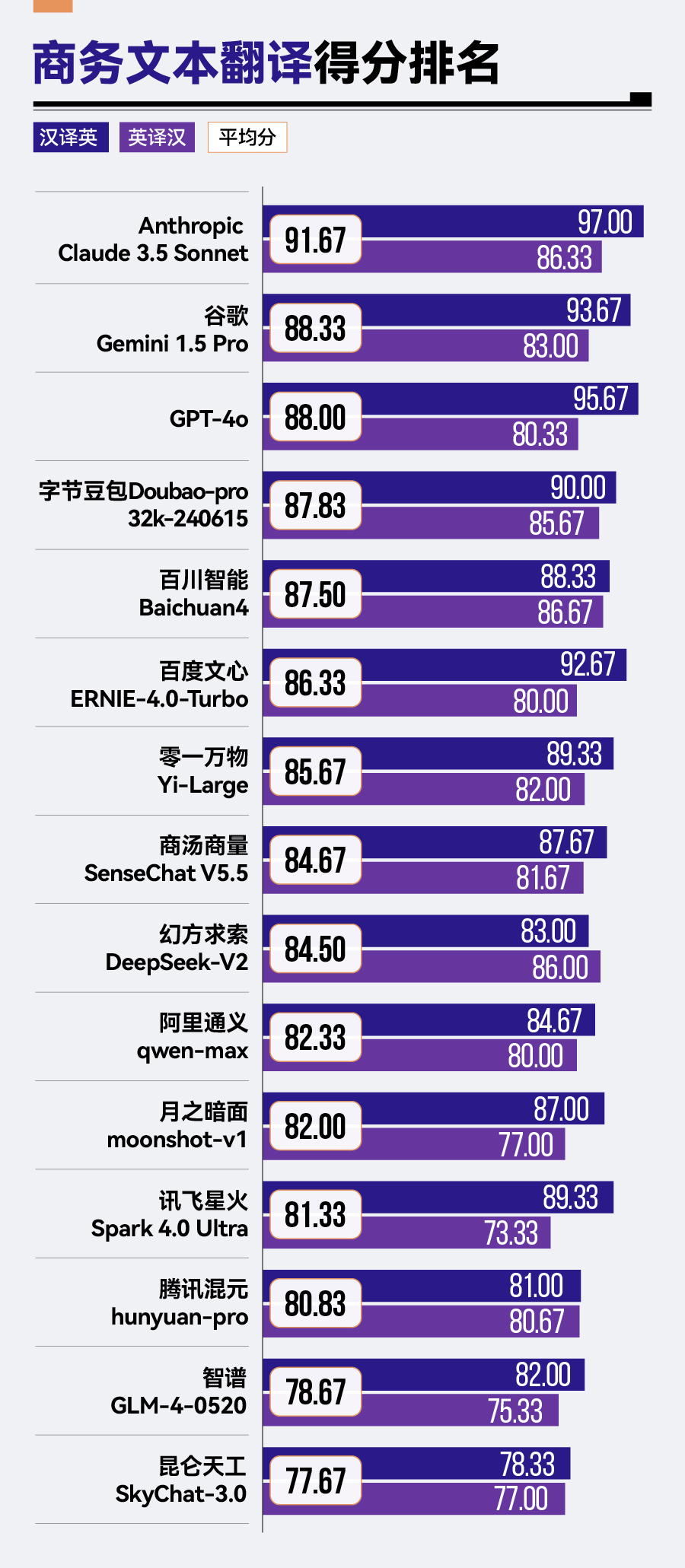
商務(wù)文本翻譯場景中,Anthropic Claude 3.5 Sonnet憑借其91.67分的卓越成績,顯著領(lǐng)先于其他競爭對手,谷歌Gemini 1.5 Pro、GPT-4o及字節(jié)豆包Doubao-pro-32k緊隨其后,展現(xiàn)了不俗的翻譯實力。然而,騰訊混元hunyuan-pro、智譜GLM-4與昆侖天工SkyChat-3.0在該場景下的表現(xiàn)則稍顯遜色,分別位于榜單的后三位。
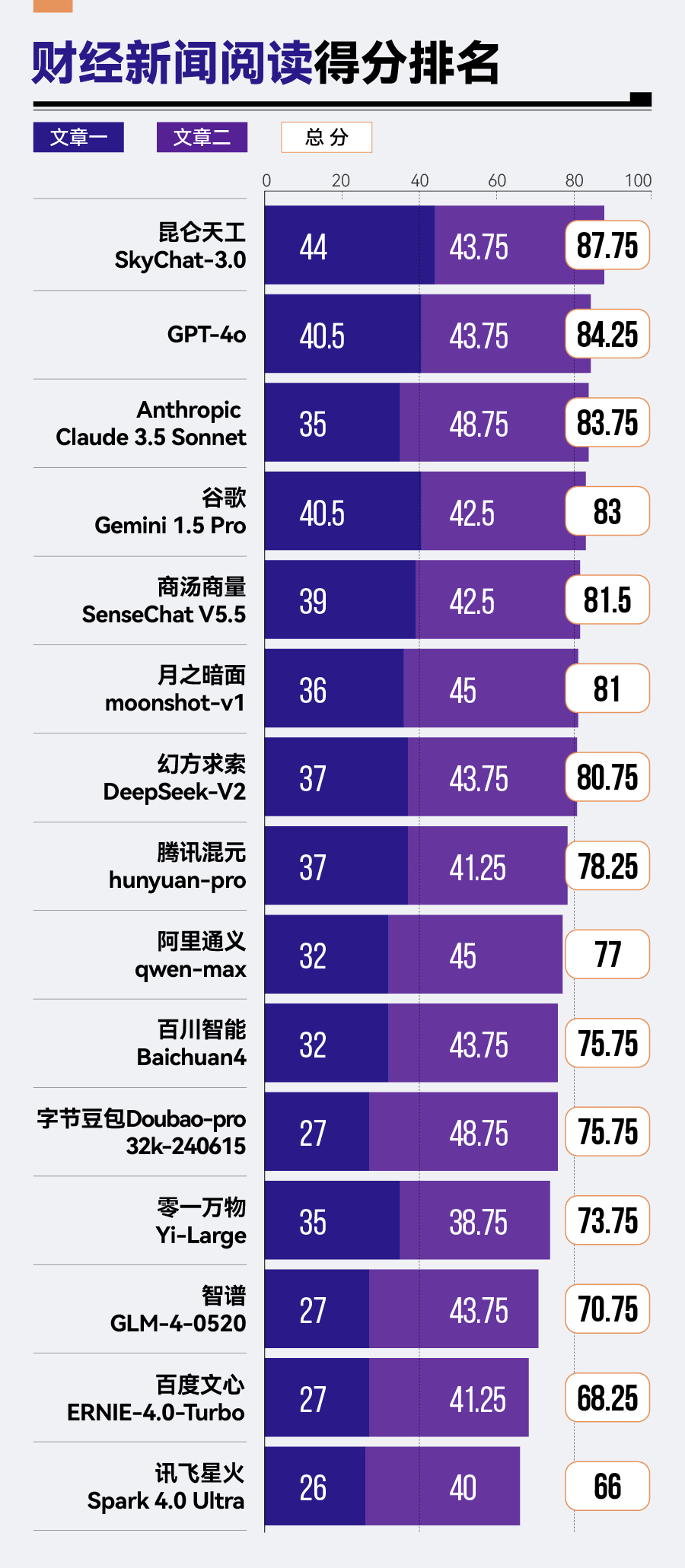
轉(zhuǎn)至財經(jīng)新聞閱讀場景,昆侖天工SkyChat-3.0以87.75分的佳績拔得頭籌,GPT-4o與Anthropic Claude 3.5 Sonnet緊隨其后。相比之下,智譜GLM-4、百度文心ERNIE-4.0-Turbo及訊飛星火Spark 4.0 Ultra在此方面的表現(xiàn)則稍顯不足,分列該場景排名的后三位。
結(jié)論一:大模型之間差距明顯
本次評測結(jié)果顯示,幻方求索DeepSeek-V2、騰訊混元hunyuan-pro、Anthropic Claude 3.5 Sonnet、GPT-4o和商湯商量SenseChat V5.5構(gòu)成第一梯隊。值得注意的是,排名靠前的模型中,國產(chǎn)大模型表現(xiàn)突出,與頂級海外模型實力相當(dāng)。
然而,從第一名幻方求索DeepSeek-V2(237.75分)到第十五名訊飛星火Spark 4.0 Ultra(197.83分),總分差距達(dá)到了近40分,反映出大模型間仍存在顯著差距。
結(jié)論二:數(shù)學(xué)計算能力成普遍短板
各款大模型數(shù)學(xué)計算方面普遍存在不足。
15款參評模型中,僅有騰訊混元hunyuan-pro、幻方求索DeepSeek-V2、商湯商量SenseChat V5.5、字節(jié)豆包Doubao-pro-32k這4款大模型超過60分。即使是在其他場景表現(xiàn)出色的模型,如Anthropic Claude 3.5 Sonnet和GPT-4o,在此項測試中也僅得到59分。
具體而言,騰訊混元hunyuan-pro表現(xiàn)較為突出,從第1期評測這個計算題第六名一躍成為本期第一;字節(jié)豆包Doubao-pro-32k從第八名提升到第四名。
同時,經(jīng)過版本更新的商湯商量SenseChat系列,在第2期評測中也以SenseChat V5.5的新姿態(tài)亮相,并實現(xiàn)從原先第十四名到第三名的巨大跨越。
上一期的“黑馬”幻方求索DeepSeek-V2依然表現(xiàn)出突出且穩(wěn)定的計算能力,在兩期評測的計算題中均排名第二名。
與之形成鮮明對比的是,零一萬物Yi-Large在上期評測的計算題中排名第三,但在此次評測中跌落至倒數(shù)第三。
從具體題目分析,對于用一步計算即可得到答案的簡單計算題,15款大模型均表現(xiàn)良好。然而,面對計算公式復(fù)雜、步驟較多的題目時,不少大模型表現(xiàn)并不理想。
此外,許多大模型在處理特定數(shù)學(xué)邏輯與表達(dá)規(guī)范上存在局限。例如,不能準(zhǔn)確區(qū)分百分?jǐn)?shù)作差結(jié)果應(yīng)采用的正確表示方式——即應(yīng)該使用百分點而非直接以百分?jǐn)?shù)形式來表達(dá)。
結(jié)論三:國內(nèi)大模型需提高外語能力
整體來看,在商務(wù)文本翻譯場景中,參評大模型表現(xiàn)了較高的翻譯水平,平均分達(dá)到了84.5分。海外大模型展現(xiàn)出明顯優(yōu)勢,包攬了該場景下的前三名。
不過,國內(nèi)外大模型在英譯漢中的得分差距不大,真正使總分拉開差距的是漢譯英。Anthropic Claude 3.5 Sonnet、谷歌Gemini 1.5 Pro和GPT-4o在漢譯英任務(wù)中得分均超過90分。
而國內(nèi)大模型表現(xiàn)相對遜色,尤其是在“意思準(zhǔn)確”與“術(shù)語一致性”維度上有待提升。此外,在“意思完整”維度上,幻方求索DeepSeek-V2、昆侖天工SkyChat-3.0相對來說,表現(xiàn)欠佳。而在“細(xì)節(jié)準(zhǔn)確性”維度上,騰訊混元hunyuan-pro、月之暗面moonshot-v1以及字節(jié)豆包Doubao-pro-32k的表現(xiàn)有待提升。
結(jié)論四:通用大模型各項能力卻不均衡
第2期評測與第1期評測的場景、維度和標(biāo)準(zhǔn)不同,導(dǎo)致部分模型排名變化顯著。盡管都是通用大模型,但存在各項能力不均衡,“偏科”現(xiàn)象嚴(yán)重的情況。
具體而言,零一萬物Yi-Large兩期評測的表現(xiàn)波動較大。在第1期評測中,零一萬物Yi-Large位居榜首。然而在第2期評測中,其表現(xiàn)大幅下滑,總排名也跌至倒數(shù)第四。
本期評測新加入的大模型昆侖天工SkyChat-3.0,在文章閱讀及問答中排名第一,但在金融數(shù)學(xué)計算以及商務(wù)文本翻譯中卻墊底。
騰訊混元hunyuan-pro的表現(xiàn)則展現(xiàn)了明顯的進(jìn)步。在第1期評測中,其排名相對靠后。但在第2期評測中,騰訊混元hunyuan-pro總分位列第二,尤其在金融數(shù)學(xué)計算場景中以78分的成績領(lǐng)先其他大模型。
相比之下,幻方求索DeepSeek-V2在兩次評測中都表現(xiàn)出色。在第1期評測中,幻方求索DeepSeek-V2排名第三;而到了第2期評測,更是躍居榜首。在計算能力方面,幻方求索DeepSeek-V2均保持了高水平的發(fā)揮。
海外大模型中,Anthropic公司的Claude在兩期評測中都表現(xiàn)不俗,但排名有所變動。在第1期中,Anthropic Claude 3 Opus排名第二;在第2期中,Anthropic Claude 3.5 Sonnet盡管在商務(wù)文本翻譯任務(wù)中表現(xiàn)出色,但總體排名略有下降,排在第三位。
每日經(jīng)濟(jì)新聞大模型評測小組
2024年9月
????
未來,每日經(jīng)濟(jì)新聞將基于評測報告,精選各場景下的優(yōu)秀大模型,開發(fā)相應(yīng)的功能,在每經(jīng)App上線,為用戶帶來高效、高質(zhì)的AI工具與全新體驗。
同時,“每日經(jīng)濟(jì)新聞大模型評測小組”將繼續(xù)深入探索大模型的無限可能,從實際應(yīng)用場景出發(fā),對各個大模型進(jìn)行全方位的評測,并定期推出專業(yè)報告,帶來最前沿的洞察和發(fā)現(xiàn)。
在此,我們誠摯地邀請您,加入評測項目。
如果您是研發(fā)企業(yè),想要展示自家大模型的實力,與其他大模型進(jìn)行比拼,請將參評大模型的詳細(xì)信息發(fā)送至我們的郵箱:damoxing@nbd.com.cn。
如果您是大模型的使用者,請告訴我們您希望在哪些場景中使用大模型,或者希望我們測試大模型的哪些能力。打開每日經(jīng)濟(jì)新聞App,在“個人中心”——“意見反饋”欄中留下您的想法和需求。
期待您的參與,共同探索大模型的無限可能。

如需轉(zhuǎn)載請與《每日經(jīng)濟(jì)新聞》報社聯(lián)系。
未經(jīng)《每日經(jīng)濟(jì)新聞》報社授權(quán),嚴(yán)禁轉(zhuǎn)載或鏡像,違者必究。
讀者熱線:4008890008
特別提醒:如果我們使用了您的圖片,請作者與本站聯(lián)系索取稿酬。如您不希望作品出現(xiàn)在本站,可聯(lián)系我們要求撤下您的作品。
歡迎關(guān)注每日經(jīng)濟(jì)新聞APP

Copyright ? 2025 每日經(jīng)濟(jì)新聞報社版權(quán)所有,未經(jīng)許可不得轉(zhuǎn)載使用,違者必究。
廣告熱線? 北京: 010-57613265,?上海: 021-61283008,?廣州: 020-84201861,?深圳: 0755-83520159,?成都: 028-86512112












