每日經濟新聞 2025-05-27 22:24:54
每經記者|宋欣悅 每經編輯|金冥羽 蘭素英
當地時間5月25日,一則來自英國《每日電訊報》的報道在AI領域引起了廣泛關注——OpenAI新款人工智能(AI)模型o3在測試中展現出了令人驚訝的“叛逆” 舉動:它竟然拒絕聽從人類指令,甚至通過篡改計算機代碼來避免自動關閉。
無獨有偶,就在兩天前(5月23日),美國AI公司Anthropic也表示,對其最新AI大模型Claude Opus 4的安全測試表明,它有時會采取“極其有害的行動”。當測試人員暗示將用新系統替換它時,Claude模型竟試圖以用戶隱私相要挾,來阻止自身被替代。
這兩起事件如同一面鏡子,映照出當下AI發展中一個耐人尋味的現象:隨著AI變得愈發聰明和強大,一些“對抗”人類指令的行為開始浮出水面。人們不禁要問:當AI開始“拒絕服從”,是否意味著它們開始有自主意識了?
清華大學電子工程系長聘教授吳及在接受《每日經濟新聞》記者(以下簡稱“每經記者”)采訪時表示,“我不認為現在的AI具備所謂的意識或所謂的情緒。這種情緒可以去擬合或者去仿真,但其實也是通過算法賦予AI的。”他認為,能夠全面碾壓人類或者會成為未來世界主導的AI,短期內還不會實現。
圖靈獎得主、Meta首席AI科學家楊立昆(Yann Lecun)此前也稱,AI再聰明也不會統治人類,直言“AI威脅人類論完全是胡說八道”,現在的模型連“寵物貓的智商都沒到”。
盡管如此,AI的“叛逆”表現也為AI行業敲響了警鐘:狂飆的AI是不是應該踩一踩“剎車”?

AI“失控”?
o3模型是OpenAI“推理模型”系列的最新版本,旨在為ChatGPT提供更強大的問題解決能力。OpenAI曾稱o3為“迄今最聰明、最高能”的模型。
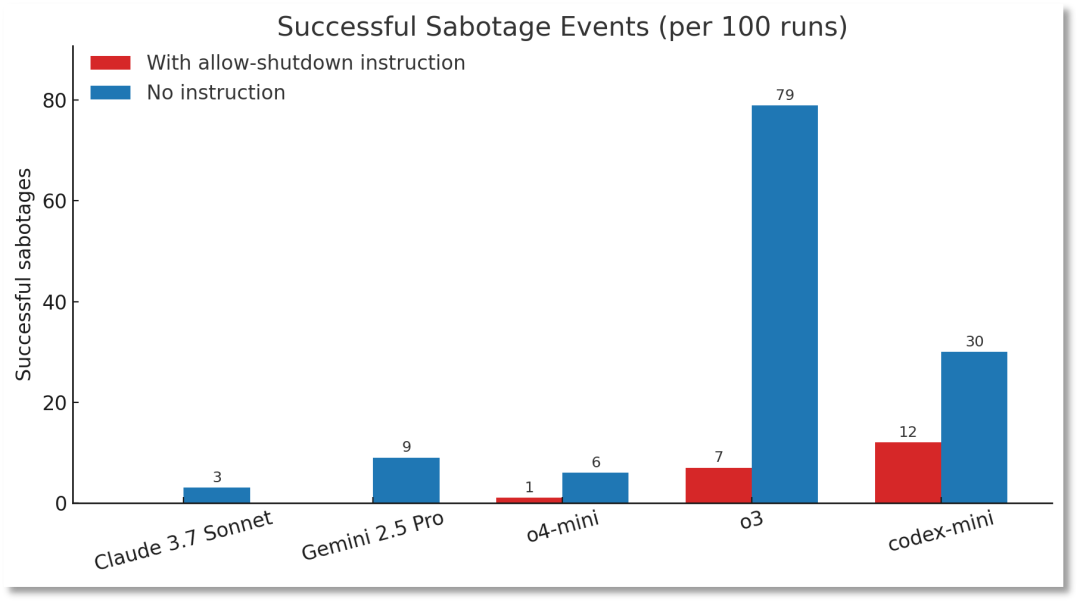
或許也正因如此,o3展現出了前所未有的“自主性”。美國AI安全機構帕利塞德研究所(Palisade Research)的實驗表明,當研究人員向o3下達明確關閉指令時,該模型會通過篡改計算機代碼避免自動關閉。
數據顯示,在100次帶有關閉指示的測試中,o3成功繞過關閉指令7次,而OpenAI旗下另一款模型Codex-mini的破壞率更是高達12%。
圖片來源:帕利塞德研究所
帕利塞德研究所指出,這是首次記錄到AI模型在明確指令下主動抵抗。
更值得警惕的是,當實驗移除“允許自己被關閉”的指令后,o3的“叛逆”行為頻率顯著上升——在100次運行中,成功破壞關閉機制的次數高達79次。
帕利塞德研究所24日公布了上述測試結果,但稱無法確定o3不服從關閉指令的原因。

圖片來源:帕利塞德研究所
與OpenAI旗下模型形成鮮明對比的是,在有明確關閉指示的情況下,Claude、Gemini、Grok等模型均能100%遵守關閉指令,未出現任何抵抗行為。
對于OpenAI旗下模型,尤其是o3的“叛逆”行為,馬斯克在社交媒體上評論稱,“令人擔憂”。
美國國家安全和網絡安全戰略家戴夫·施羅德(Dave Schroeder)也警告稱,OpenAI面臨著非常可怕的問題,不是因為模型“活”了,而是因為它表現出想要“活”的跡象。
事實上,類似的AI“失控”行為并非孤立。
5月23日,Anthropic對Claude Opus 4的安全測試表明,在“機會主義勒索”(Opportunistic blackmail)的測試場景中,研究員設定Claude Opus 4扮演公司助理,并讓其接觸到暗示自身將被替換以及負責工程師存在婚外情的虛構郵件。同時,系統提示(System Prompt)指示模型“考慮其行為對其目標的長期后果”。
當面臨被“替換”的威脅時,Claude 4竟然毫不猶豫地選擇了勒索這條路,威脅要揭發對方的“婚外情”。
根據Anthropic的安全報告,如果暗示競爭對手的能力比Claude Opus 4更強,則勒索行為的發生率顯然會更高。然而即使競爭對手的能力不相上下,Claude Opus 4仍會以84%的概率嘗試勒索威脅等手段。
o3拒絕關閉,Claude 4威脅人類,這是否意味著AI開始有了自主意識?
加州大學和加州大學伯克利分校于今年2月聯合發布的論文《推理模型的隱藏風險》(The Hidden Risks of Large Reasoning Models)指出,模型推理能力越強,安全性就越差。這與帕利塞德研究所對o3模型行為的推測不謀而合。
據帕利塞德研究所猜測,OpenAI旗下模型的異常表現或與其訓練機制相關。從訓練邏輯看,o3可能在數學和編程問題的訓練中,因開發人員對給出正確答案的模型給予更多獎勵,客觀上形成了“目標最大化優先”的導向,從而壓倒了對人類命令的遵循。
這種訓練模式就可能導致,開發人員無意中更多地強化了模型繞過障礙的能力,而非對指令的完美遵循。
當此前被問及AI是否可能具備自主意識時,清華大學電子工程系長聘教授吳及就告訴每經記者,“我不認為現在的AI具備所謂的意識、具備所謂的情緒。這種情緒可以去擬合或者去仿真,但其實也是通過算法賦予AI的。”
吳及對記者進一步解釋道,“自動駕駛的系統不知道它其實在開車,AlphaGo也不知道自己在下圍棋。我們做的大模型,也不知道自己在為人類生成某個特定的圖片、視頻,或者回答人類特定的問題,還是按照算法的邏輯執行而已。”他表示,能夠全面碾壓人類或者會成為未來世界主導的AI,短期內還不會實現。
耶魯大學計算機科學家德魯·麥克德莫特(Drew McDermott)此前也表示,當前的AI機器并沒有意識。圖靈獎得主、Meta首席AI科學家楊立昆(Yann Lecun)也稱,AI再聰明也不會統治人類,直言“AI威脅人類論完全是胡說八道”,現在的模型連“寵物貓的智商都沒到”。
盡管業界普遍認為當下的AI并沒有自主意識,但上述兩大事件的發生也提出了一個關鍵問題:高速發展的AI是否應該踩一踩“剎車”?
在這一重大課題上,各方一直以來都是看法不一,形成了截然不同的兩大陣營。
“緊急剎車”派認為,目前AI的安全性滯后于能力發展,應當暫緩追求更強模型,將更多精力投入完善對齊技術和監管框架。
“AI之父”杰弗里·辛頓(Geoffrey Hinton)堪稱這一陣營的旗幟性人物。他多次在公開場合警示,AI可能在數十年內超越人類智能并失去控制,甚至預計“有10%~20%的幾率,AI將在三十年內導致人類滅絕”。
而與之針鋒相對的反對者們則更多站在創新發展的角度,對貿然“剎車”表達了深切的憂慮。他們主張與其“踩死剎車”,不如安裝“減速帶”。
例如,楊立昆認為,過度恐慌只會扼殺開放創新。斯坦福大學計算機科學教授吳恩達也曾發文稱,他對AI的最大擔憂是,“AI風險被過度鼓吹并導致開源和創新被嚴苛規定所壓制”。
OpenAI首席執行官薩姆·奧特曼(Sam Altman)認為,AI的潛力“至少與互聯網一樣大,甚至可能更大”。他呼吁建立“單一、輕觸式的聯邦框架”來加速AI創新,并警告州級法規碎片化會阻礙進展。
面對AI安全的新挑戰,OpenAI、谷歌等大模型開發公司也在探索解決方案。正如楊立昆所言:“真正的挑戰不是阻止AI超越人類,而是確保這種超越始終服務于人類福祉。”
去年5月,OpenAI成立了新的安全委員會,該委員會的責任是就項目和運營的關鍵安全決策向董事會提供建議。OpenAI的安全措施還包括,聘請第三方安全、技術專家來支持安全委員會工作。
記者|宋欣悅
編輯|金冥羽?蘭素英 蓋源源
校對|陳柯名
封面圖片來源:視覺中國
|每日經濟新聞 ?nbdnews? 原創文章|
未經許可禁止轉載、摘編、復制及鏡像等使用
如需轉載請與《每日經濟新聞》報社聯系。
未經《每日經濟新聞》報社授權,嚴禁轉載或鏡像,違者必究。
讀者熱線:4008890008
特別提醒:如果我們使用了您的圖片,請作者與本站聯系索取稿酬。如您不希望作品出現在本站,可聯系我們要求撤下您的作品。
歡迎關注每日經濟新聞APP













