每日經濟新聞 2024-07-10 13:07:41
◎ 斯坦福大學等高校以及Meta的學者提出了一種全新的大語言模型架構,有望代替至今在AI領域如日中天的Transformer,性能也比Mamba更好。
每經記者|蔡鼎 每經編輯|蘭素英
從2017年Google Brain團隊推出Transformer架構逐步取代長短期記憶(LSTM)等“循環神經網絡(RNN)模型”成為首選模型,到后來首個線性時間序列架構Mamba推出又對Transformer架構構成挑戰,大語言模型底層架構的迭代正在迅速改變人們對于AI的認知和理解。
美東時間周一(7月8日),一種全新的大語言模型(LLM)架構有望代替至今在AI領域如日中天的Transformer,性能也比Mamba更好。

圖片來源:arXiv
在預印本網站arXiv上發布的一篇論文中,斯坦福大學、加州大學伯克利分校、加州大學圣地亞哥分校和Meta的學者提出了一種全新架構,希望能用機器學習模型取代RNN的隱藏狀態。這個架構通過對輸入token進行梯度下降來壓縮上下文,被稱為“測試時間訓練層(Test-Time-Training layers,簡稱TTT層)”。“共同一作”加州大學伯克利分校的Karen Dalal表示,我相信這將從根本上改變語言模型。
但對于該論文,也有人提出質疑,認為只有30億~70億參數的可用演示模型才足以了解其實用性。
過去這些年來,對大模型的研究和理解都繞不開“循環神經網絡(下稱RNN)”。RNN是一種深度學習模型,由許多相互連接的組件組成,經過訓練后可以處理順序數據輸入并將其轉換為特定的順序數據輸出,例如將文本從一種語言翻譯成另一種語言。順序數據是指單詞、句子或時間序列數據之類的數據,其中的順序分量根據復雜的語義和語法規則相互關聯。
而“隱藏狀態”是RNN模型中的一個關鍵概念。它可以看作是網絡在每個時間步驟上的“記憶”,存儲了之前時間步驟中的信息,并通過時間在不同步驟之間傳遞。隱藏狀態可以捕捉到序列中的長期依賴性,從而使模型能夠理解整個序列的上下文。
在傳統的RNN中,隱藏狀態的固定大小表達能力受限,也不好并行訓練。例如,像Mamba這樣的RNN層,會隨著時間的推移壓縮成一個固定大小的狀態,它們雖然效率很高,但性能受限于其表達能力。
該論文團隊的對TTT層的想法來自于:與其讓RNN隱藏狀態被動地儲存信息,不如讓它主動學習。作者們在論文中稱,他們設計的“TTT層”突破了“RNN層”在長上下文中性能受限的問題。
他們在1.25億~ 13億個參數規模的大模型上進行一系列的對比后發現,他們設計的TTT-Linear(線性模型)和TTT-MLP (注:MLP為多層感知器,是一種基于前饋神經網絡的深度學習模型)均能匹敵或擊敗最強大的Transformers和 Mamba架構方法。
論文稱,隱藏狀態時線性模型的TTT-Linear表現超過了Transformer和Mamba,用更少的算力達到更低的困惑度(下圖左),也能更好利用長上下文(下圖右)。此外,隱藏狀態時MLP模型的TTT-MLP在32k長上下文時表現還要更好。
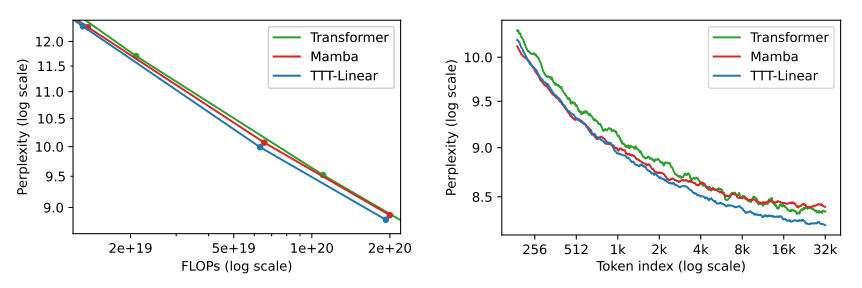
圖片來源:arXiv
這不僅在理論上是線性的復雜度,而且實際運行時間也更快。
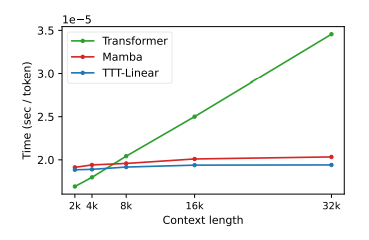
圖片來源:arXiv
本篇論文一共有12名作者,有一半(6人)成員為華人。其中,排名第一的“一作”Yu Sun博士畢業于加州大學伯克利分校電氣工程與計算機科學系,目前是斯坦福大學的博士后,研究重點便是TTT的算法架構。排在第二位的“一作”Xinhao Li為加州大學圣地亞哥分校研二學生,其研究集中在深度學習和計算機視覺,“三作”之一的Xiaolong Wang為其導師。

Yu Sun 圖片來源:個人主頁
論文稱,Yu Sun于2022年11月便開始和Xinhao Li做這個項目,2023年6月份開始進入全職工作狀態。Yu Sun提出了項目的概念框架,設計了小批量的TTT層和“雙重形式”,在他人的幫助下撰寫了論文,并領導了整個團隊的日常運作和實驗。
該研究“一作”之一 、加州大學伯克利分校信息工程學系學生Karen Dalal在X上表示,他相信這將從根本上改變語言模型。他稱,“我們設計了一個新的架構,用機器學習模型取代了RNN的隱藏狀態。該模型通過輸入標記的實際梯度下降來壓縮上下文。我們將我們的方法稱為‘測試時間訓練層’。TTT層通過表達性記憶解鎖了線性復雜性架構,使我們能夠在上下文中用數百萬(有朝一日甚至數十億)個token來訓練大語言模型。”

圖片來源:X
Karen Dalal還稱,“TTT-Linear已經比最快的SSM(注:指‘狀態空間模型’)更快,并且在大小和上下文方面具有很強的可擴展性。這個架構內的探索空間是巨大的,我們的論文只是邁出了一小步。”
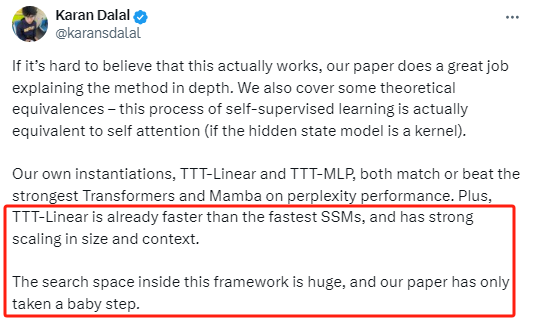
圖片來源:X
該論文的“三作”之一、加州大學伯克利分校博士后,現加州大學圣地亞哥分校電氣與計算機工程助理教授Xiaolong Wang則在X上激動地稱:“我真不敢相信這終于發生了。”
“TTT層理念是我們已經研究了5年的架構……今天的TTT和我剛開始做博士后研究的時候已經完全不同了,它已經是一個網絡層,用機器學習模型取代了RNN的隱藏狀態。我們的TTT層并不是使用特定的向量來表達記憶,而是維護一個小型神經網絡來壓縮輸入標記……這種架構目前應用于語言建模,但想象一下將其應用于視頻。未來,在長視頻建模時,我們可以對幀進行密集采樣,而不是以1 FPS的速度采樣,這些密集的幀對Transformer架構來說是負擔,但對TTT層來說卻是福音。因為它們本質上只是在TTT內訓練更好網絡的‘時間增強’。”
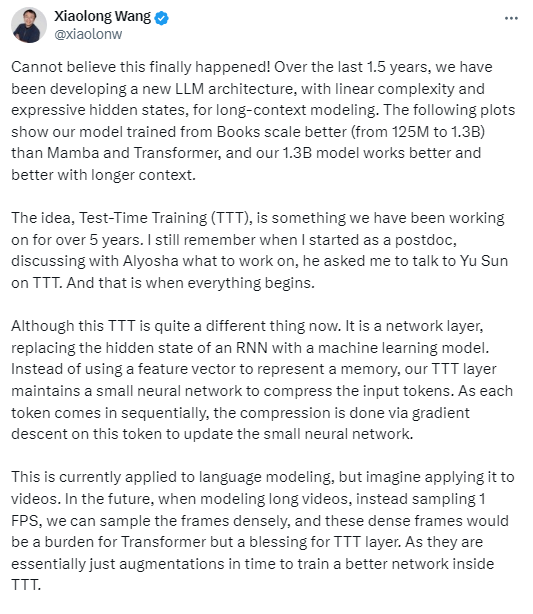
圖片來源:X
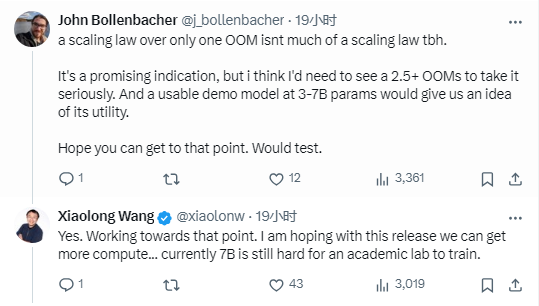
《每日經濟新聞》記者注意到,在Xiaolong Wang的推文下方,也有不少質疑者,例如,一個名為John Bollenbacher的用戶稱,“這是一個有希望的跡象,但我認為我需要看到2.5個以上的示例才能認真對待。而一個30億~70億參數的可用演示模型才可以讓我們了解它的實用性。”
對此,Xiaolong Wang回復稱,“(我們正)朝著那個方向努力。我希望通過這個版本我們可以得到更多的計算……就目前而言,學術實驗室仍然很難訓練70億參數的模型。”
圖片來源:X
如需轉載請與《每日經濟新聞》報社聯系。
未經《每日經濟新聞》報社授權,嚴禁轉載或鏡像,違者必究。
讀者熱線:4008890008
特別提醒:如果我們使用了您的圖片,請作者與本站聯系索取稿酬。如您不希望作品出現在本站,可聯系我們要求撤下您的作品。
歡迎關注每日經濟新聞APP














